
ここ数年ディープラーニングをはじめとする機械学習が周りでホットトピックになっていて、すごいなあと思いつつ、僕みたいな人間には難しすぎて理解が追いつかない部分がたくさんある。要するに僕は、技術そのもののエポックさからいろいろ想像することができるほど技術そのものを理解できていなくて、「それを使ってこんなことができました!」という事例を見る方が好きというか、単純に想像力が刺激されるんですよね。だから昔から計算機をつかって絵を描こうという初期のコンピュータグラフィックスの研究や、画像や音楽を生成するみたいな試みがグッとくるし、それを見ることで少し技術への理解が深まったような気になってうれしい。少し軽薄かもしれないけれども。というわけで、今日は機械学習周りで面白いなあと思っている事例をあれこれまとめてみました。※いろいろ認識が間違っている部分もあると思うのでツッコミをいれてもらえるとうれしいです。
■コンピュータに自力で猫を見つけさせる

Building High-level Features Using Large Scale Unsupervised Learning, 2012
ここ数年機械学習が急速に注目されるようになったのは2012年くらいからで、当時話題になったのがこの研究。個人的に興味を持ったのもこのへんが入り口なので紹介しておきます。「Googleの研究チームがコンピュータに猫を理解させた」というキャッチーな触れ込みで大きな話題になったの研究。Googleが具体的に何をしたかというと...
1)YouTubeにアップロードされている動画から、ランダムに取り出した200x200ピクセルサイズの画像を1000万枚用意
2)1000台のコンピュータ3日間計算させ続けた(多段階のニューラルネットワークによる機械学習)
3)そもそも最初は「人の顔だと教えずに顔を抽出できるようになるか」という研究だったが、上記の解析の結果、写真を入力すると「人」「猫」「人間の身体」に反応する「ニューロン」ができた。
要するに、何かしらの画像をみせたときに、コンピュータがおぼろげに「顔っぽい」「猫っぽい」「人間の身体っぽい」にだけピコッと反応する機能が副産物としてできましたということ。で、Googleはそのニューロンが最も強く反応する画像を生成したところ、上の画像が生成されたというわけ。これはコンピュータが認識しているおぼろげな「猫の概念」を画像にしたもの、といえます。※画像の生成って?とハテナになった方は以前書いたこちらの記事をご覧ください。認識器の作り方のアプローチは違うけど、生成部分については近しいことをやっているという認識です。)
いわゆるディープラーニングというものが大きな話題になってきたのはちょうどこの時期で、ちょうど同年のImageNet Large Scale Visual Recognition Challengeという画像認識コンテストで、トロント大学の研究チームが開発した、多段階ニューラルネットワークを利用したsupervisionという画像認識アルゴリズムがこれまでの認識精度を一気に跳ね上げた(一つ前の年に優勝したアルゴリズムの正答率が73.8%だったのが、supervisionは83.6%という正答率をたたき出した)というのも追い風になっているとか。(ちなみにその2年後の2014年のILSVRCでは、同じくディープラーニングを利用したGoogleのGoogLeNetというアルゴリズムが93.3%という数値をたたき出している)
■コンピュータにゲームを解かせる
通称DQNってやつですねw。2014年にGoogleが4.5億ドルで買収したDeepmind Technologiesによる技術で、機械学習の中でも強化学習というものにフォーカスをあてて、プログラムにゲームをひたすらプレイさせていくことで高得点を出すためのルールをプログラムが学習してハイスコアを叩き出すというもの。ちなみに先日話題になったAlphaGoもDeepmindによって開発されたものです。
「コンピュータに問題を解かせる」という点で、コンピュータゲームは機械学習の研究との相性が良くて、2009年〜2012年の3年間、Mario AI Championshipというコンペが行われていて、これはjava環境でエミュレートしたスーパーマリオをプログラムにプレイさせてスコアを競う部門、ステージの自動生成の出来栄えを競う部門などがあったようです。
なお、実際のゲーム制作の現場でもゲームを解くプログラムをつくって、それによってレベルデザインを行っているという事例もあるようです。こちらは国内でデザインがイケてるボードゲームやスマホゲームを開発しているoink gamesによる遺伝的アルゴリズムを用いたレベルデザインについての記事。
■画像を描かせる

Google Deepdream。一時期この画像が大量にタイムラインにシェアされて苦しい思いをした人も多いのではw 機械学習で画像を認識する技術を応用して、入力した写真が何かを出すのではなく、入力された写真の中にあらかじめ学習させた画像を「連想」させるようにプログラムした結果、人間が壁のシミに顔が見えてくるような「シミュラクラ現象」に近い現象をコンピュータに再現させることに成功したということに近いかと。雲の写真を見せると「あれは魚に見えるなあ」とか「あれはなめくじみたいだ」っていうのをコンピューターにやらせてみた、という感じですね。面白いのは、このプログラムの出力結果が、Alex GreyのようなLSDによるサイケデリック体験を描いているアーティストの作品に非常に似たテイストを持っているということ。ドラッグによって感覚が麻痺すると人間の脳内でこのプログラムと同じような認知プロセスが動いているのかもしれないと考えるとめちゃくちゃおもしろいですよね。Deep Dreamはここで試せます。
A Neural Algorithm of Artistic Style
コーネル大学が発表した"A neural Algorithm of Artistic Style"通称Style Netというアルゴリズム。特定の画家の画像や写真など、お手本となる「スタイル画像」を訓練させたニューラルネットを流用することで、任意の画像にスタイルを適応できる...つまりゴッホの絵を訓練させればゴッホ風フィルタがつくれるし、ムンクの絵を訓練させればムンク風フィルタがつくれる、という面白い技術です。こちらの記事で仕組みも含めて詳しく解説されています。
■コンピュータに萌えイラストを描かせる
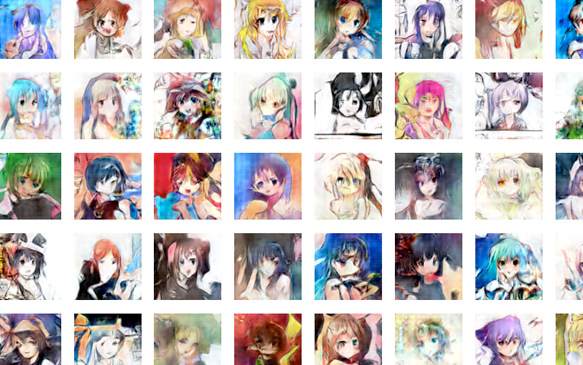
DCGAN(Deep Convolutional Generative Adversarial Networks)とよばれる画像を生成するニューラルネットを利用して、Safebooru(http://safebooru.org/)というアニメイラストを集めてきて学習させたプログラムに様々なアニメ絵を生成させるという実験です。アイコンサイズですが、ものすごく精度の高いイラストが生成されて驚きます。かつ髪の色や服などのパラメーターが細かく設定できるのもすごい...こちらの記事に詳しい解説が掲載されています。
■コンピュータに人間のお絵描きをサポートさせる
前述のStyle Netの考え方を推し進め、人間のお絵描きをサポートするという目的に適応したのがこのNeural Doodles (Semantic Style Transfer)と呼ばれるプロジェクト。Style Netのような仕組みとお絵描きソフトのUIを組み合わせることで、らくがきを簡単に名画風にレンダリングできる技術です。「ディープラーニング版 ボブの絵画教室」という感じでしょうか。写真から絵を生成するのではなく、人のお絵描きをサポートしていくというアプローチが面白いですね。
人のお絵描きをサポートする方向でいえば、2012年SIGGRAPHで発表されたHow Do Humans Sketch Objects?もとても面白い研究です。2万件を超える手書きイラストのデータを学習させてリアルタイムに描いているものを推測させるというシステム。
そしてこちらは上記システムを用いて、プロのイラストレーターに絵を書いてもらいながら、システムがどのようにそのイラストを認識しているかを合成音声に読み上げさせたもの。子供に対して絵あてゲームをやっているようで面白いですね。こちらの記事ではAssisted Drawingについての様々な研究が紹介されていて読み応えがあります。
■コンピュータに漢字っぽいものを書かせる

Random Radicals: A Fake Kanji Experiment
ここまで画像を学習させて画像を生成させるというアプローチが多かったのですが、今度はこれを文字にした変わり種のプロジェクトです。これはSVGで描かれた漢字に筆順や文字コードなどのメタデータを付加されているKanjiVGというデータベースの情報を学習させたプログラムに、ひたすら漢字っぽい文字を書かせるというプログラムです。プログラムが延々漢字っぽいものを書いていくのを見るとなんだか不思議な気分になります。その年のニュースのテキストを解析させて、「今年を表す創作漢字」をこのプログラムにつくらせたりしたら面白いかも。詳しくはこちらの記事をどうぞ。
■コンピュータに画像と画像の間を補間させる
こちらもGoogleによる研究で、画像を生成する技術をGoogle Streetviewなどで収集した静止画と静止画の間の画像を推定して生成することによって静止画と静止画の間をスムーズに遷移させるという技術。いわゆるフレーム補間はビデオ編集の領域で古くから導入されている技術ですが、機械学習を取り入れることによってよりスムーズな補間を可能にするとのこと。
■モノクロ画像に色をつける
モノクロ画像に畳み込みニューラルネットワーク(CNN)という機械学習を利用して彩色する研究。フルカラー画像さえ用意できれば、モノクロ画像は画像を減色するだけで生成できるので、答え合わせをひたすらしていくことで精度を高めることができるところがミソとか。ImageNetの画像をつかったモデルが配布されていますが、ソースを変えていくとそれぞれの対象毎により精度の高い推定ができるようになるのかもしれません。詳しくはこちらの記事でかわかりやすく解説されています。
■コンピュータに画像を説明させる
Deep Visual-Semantic Alignments for Generating Image Descriptions、通称Neural Talk。画像と画像に付属したキャプションのデータセットを訓練させて、画像から説明文を自動生成する研究...ここまでくると技術的な説明を読んでももはやちんぷんかんぷんなのですが、こちらの資料で詳しい解説がされています。
上記の映像は、NeuralTalkをWebcamで使えるように改造してアムステルダムの街を歩きながら撮影した映像にキャプションをつけたもの。上のHow Do Humans Sketch Objects?で紹介した映像もそうですが、なんだか子供をつれて歩いているような感じがすごく不思議です。
さらにNeuralTalkを利用してレーザーディスクカラオケの味映像から歌詞を自動生成する試みまでw!→ 「昭和後期の民俗学的映像データ再活用をめぐって - 畳み込みニューラルネットワークによる情景分析とその応用」
■コンピュータに演説させる
再帰型ニューラルネットワーク(RNN)という機械学習を利用してオバマの過去の演説を学習させたプログラムにそれっぽい演説を生成させたり、TED talkを生成させたりしている事例。コンピュータは意味を生み出すのは難しいけど「っぽさ」を模倣するのが得意ということがなんとなくわかる事例だと思います。
「っぽさ」というものは「ものまね」とかもそうですけど、なんとなく感じるものでかなり注意深く対象を観察しないと再現するのは難しいもの。機械学習によってコンピュータに何かを学習させるというのは「っぽさ」をコンピュータに見つけさせるという試みなのかもしれません。「猫っぽさとは何か」「人の顔っぽさとは何か」「ゴッホっぽさとは何か」「オバマっぽさとは何か」などなど...※ちょっと紹介するのが憚られますがw 最近みて面白かったのはこれ、これはつまり「巨乳っぽい顔」というものをコンピュータに訓練させようという試みですねw
その「っぽさ」を使ってさらに人間が何をするか、というところが面白いプロジェクトが今後重要になっていくのかな、と個人的には思います。たとえば、Instagramの自分撮り画像を解析して、たくさんのLikeがついている画像を学習させたこちらのプロジェクトは、良い写真とは何か、ということに対するヒントをもらうことができます。コンピュータの解析結果から人間が何を学べるのか、そこから文化がどのように変化していくのか、とても気になります。
ざっと歴史を掴むのに、この本わかりやすかったです。

KADOKAWA/中経出版
売り上げランキング: 342